NSF Big-Data Theoretic

As part of the Soteria lab team I worked on the web scraping of the Nuclear Regulatory Commission’s (NRC) website for event reports from nuclear power plants and was involved in the subsequent cleaning and management of this text data. Part of the NSF-funded “Big-Data Theoretic” project, I worked under the guidance of Justin Pence and my work was acknowledged in two journal articles and his Ph.D. dissertation. You can find the articles here and here.
Risk Assessment tends to be very important when it comes to nuclear power plants. In industries like nuclear and aerospace, catastrophic failure tends to be a low-frequency high-consequence event. As opposed to deterministic risk assessment, Probabilistic Risk Assessment (PRA) is a comprehensive methodology to model common cause failures, human errors and assumes even rare events can occur. The end goal for analyzing the text data was to try and find organizational factors that contribute to undesirable events which would then be quantified and used as a base input into PRA. The text mining after our initial extraction and pre-processing was carried out by collaborators in the iSchool, UIUC.
Extraction
As any good web-scraper knows, webpage variability is the bane of many a well written script. And government websites exemplify this the best. However, as much as I would like to show the website we had to deal with, the NRC has since made amends and the new website is much better. For my work, the presence of hidden dropdown menu’s and other such webpage elements meant Selenium Webdriver had to be used. On the data managent side, I’d recommend checking out shutil for incorporating file operations into any script; it was very useful in dealing with over 15k event reports spanning 3 decades.
Cleaning
Event Reports are generated for every small noticeable event that happens in the system in question. From pipe breakage to an alarm system malfunctioning, 100s of such reports are generated daily in power plants across the US.
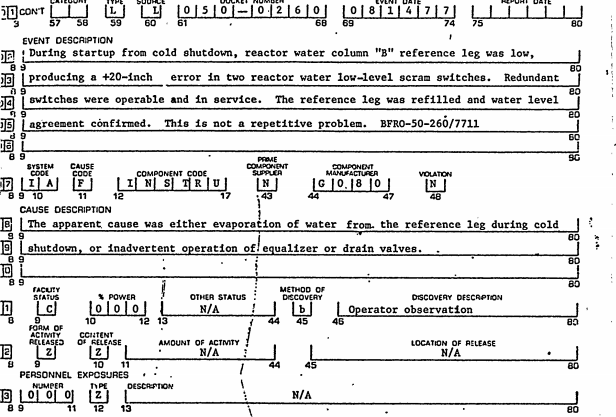
These event reports were available as text files which were the result of OCR. Now, OCR on the above shown example does not yield a pretty result. The files had all kinds of extraneous text mixed in with the actual meat of the report – sections such as title, description, conclusion etc. There were some common denominators such as table properties and these were eliminated using regular expressions. The remainder of the illegible text was dealt with using nltk and NLP methods.
Further Reading:
- Justin’s thoughts on risk informed internet regulation - his medium article and website.
- Big-Data Theoretic project page.
- Dr Zahrah Mohaghegh is the Soteria Lab PI and her focus is PRA in nuclear systems.